https://zhuanlan.zhihu.com/p/34433581https://www.cnblogs.com/pinard/p/10609228.html近年来,深度强化学习(DRL)一直是人工智能(AI)一些重大突破的核心。然而,尽管DRL方法取得了很大的进步,但由于缺少工具和库,它仍然难以应用于主流解决方案中。因此,DRL在很大程度上仍然是一种研究活动,并没有在现实世界中大量采用机器学习解决方案。解决这个问题需要更好的工具和框架。在当前一代人工智能(AI)领导者中,DeepMind是唯一一家在推进DRL研发方面做得最多的公司。最近,Alphabet子公司发布了一系列新的开源技术,可以帮助简化DRL方法的采用。DRL作为一种新的深度学习技术,其应用面临的挑战不仅仅是算法的简单实现。需要训练数据集、环境、监测优化工具以及精心设计的实验来简化DRL技术的采用。考虑到DRL的机制与大多数传统机器学习方法不同,这一点在DRL的情况下尤其正确。DRL代理试图在给定的环境中通过反复试验来掌握任务。在这种情况下,环境和实验的鲁棒性对DRL代理开发的知识起着重要的作用。DRL一直是DeepMind推进人工智能的基石。从著名的AlphaGo开始,到医疗、生态研究、当然还有游戏等领域的重大里程碑,DeepMind已将DRL方法应用于重大人工智能挑战。为了实现这些里程碑,DeepMind不得不构建许多专有工具和框架,以简化对DRL代理的大规模培训、实验和管理。DeepMind非常低调地公开了其中的一些技术,以便其他研究人员可以使用它们来推进DRL方法的当前状态。最近:DeepMind开源了三个不同的DRL堆栈,值得进行更深入的探索。 OpenSpiel  游戏在DRL agent的训练中发挥着重要的作用。与其他数据集不同,游戏本质上是基于测试和奖励机制,这些机制可用于训练DRL代理。然而,正如你所能想象的那样,游戏环境的组装绝非易事。OpenSpiel是一个环境和算法的集合,用于研究游戏中的一般强化学习和搜索/规划。OpenSpiel的目的是在许多不同的游戏类型中促进一般的多智能体强化学习,其方式与一般的游戏玩法类似,但强调学习而不是竞争形式。当前版本的OpenSpiel包含了超过20种不同类型的游戏的实现(完美的信息、同时移动、不完美的信息、网格世界游戏、拍卖游戏和一些标准形式/矩阵游戏)。DeepMind的通用学习算法让机器可以通过游戏化学习,尝试获得类人的智力和行为。OpenSpiel的核心实现基于c++和Python绑定,这有助于在不同的深度学习框架中采用它。该框架包含一个游戏组合,允许DRL代理掌握合作和竞争行为。类似地,OpenSpiel包含了多种DRL算法,包括搜索、优化和单代理。 SpriteWorld
游戏在DRL agent的训练中发挥着重要的作用。与其他数据集不同,游戏本质上是基于测试和奖励机制,这些机制可用于训练DRL代理。然而,正如你所能想象的那样,游戏环境的组装绝非易事。OpenSpiel是一个环境和算法的集合,用于研究游戏中的一般强化学习和搜索/规划。OpenSpiel的目的是在许多不同的游戏类型中促进一般的多智能体强化学习,其方式与一般的游戏玩法类似,但强调学习而不是竞争形式。当前版本的OpenSpiel包含了超过20种不同类型的游戏的实现(完美的信息、同时移动、不完美的信息、网格世界游戏、拍卖游戏和一些标准形式/矩阵游戏)。DeepMind的通用学习算法让机器可以通过游戏化学习,尝试获得类人的智力和行为。OpenSpiel的核心实现基于c++和Python绑定,这有助于在不同的深度学习框架中采用它。该框架包含一个游戏组合,允许DRL代理掌握合作和竞争行为。类似地,OpenSpiel包含了多种DRL算法,包括搜索、优化和单代理。 SpriteWorld 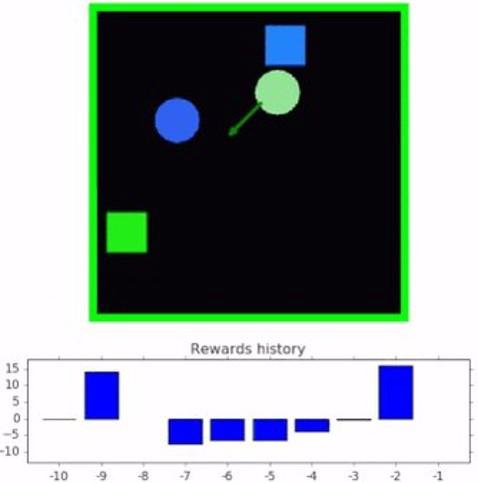 几个月前,DeepMind发表了一篇令人印象深刻的研究论文,介绍了一种基于好奇对象的搜索代理(COBRA),它使用强化学习来识别给定环境中的对象。眼镜蛇特工接受了一系列二维游戏的训练,在这些游戏中,人物可以自由移动。用于训练COBRA的环境被称为SpriteWorld,它是DeepMind最近的开源贡献之一。Spriteworld是一个基于python的RL环境,它由一个可以自由移动的简单形状的二维竞技场组成。更具体地说,SpriteWorld是一个二维的正方形竞技场,拥有数量可变的彩色精灵,可以自由地放置和渲染,没有遮挡,但是也不会发生碰撞。SpriteWorld环境基于一系列关键特征:
几个月前,DeepMind发表了一篇令人印象深刻的研究论文,介绍了一种基于好奇对象的搜索代理(COBRA),它使用强化学习来识别给定环境中的对象。眼镜蛇特工接受了一系列二维游戏的训练,在这些游戏中,人物可以自由移动。用于训练COBRA的环境被称为SpriteWorld,它是DeepMind最近的开源贡献之一。Spriteworld是一个基于python的RL环境,它由一个可以自由移动的简单形状的二维竞技场组成。更具体地说,SpriteWorld是一个二维的正方形竞技场,拥有数量可变的彩色精灵,可以自由地放置和渲染,没有遮挡,但是也不会发生碰撞。SpriteWorld环境基于一系列关键特征:- 多对象竞技场反映了现实世界的构成,杂乱的物体场景可以共享功能,但可以独立移动。这还提供了测试与任务无关的特性/对象的健壮性和组合泛化的方法。
- 连续点击-推送动作空间的结构反映了世界空间和运动的结构。它还允许代理向任何方向移动任何可见对象。
- 对象的概念不以任何特权方式提供(例如操作空间中没有对象特定的组件),并且可以被代理完全发现。
- SpriteWorld对每个DRL代理进行三个主要任务的培训:
- Goal-Finding。agent必须将一组目标对象(可通过某些特征识别,如“绿色”)带到屏幕上的隐藏位置,忽略干扰物对象(如非绿色)
- 排序。代理必须根据对象的颜色将每个对象带到目标位置。
- 集群。代理必须根据对象的颜色将其分组。
bsuite  强化学习行为套件(bsuite)试图成为强化学习的MNIST。具体来说,bsuite是一组实验,旨在突出代理可伸缩性的关键方面。这些实验体现了一些基本的问题,例如“探索”或“记忆”,其方式可以很容易地测试和迭代。具体来说,bsuite有两个主要目标:收集清晰、信息丰富和可扩展的问题,以捕捉设计高效和通用学习算法中的关键问题。通过代理在这些共享基准上的性能来研究代理行为。bsuite的当前实现实现了跨不同环境自动执行这些实验,并收集了相应的指标,这些指标可以简化DRL代理的培训。正如你所看到的,DeepMind一直非常积极地开发新的强化学习技术。OpenSpiel、SpriteWorld和bsuite对于开始强化学习之旅的研究团队来说是不可思议的资产。
强化学习行为套件(bsuite)试图成为强化学习的MNIST。具体来说,bsuite是一组实验,旨在突出代理可伸缩性的关键方面。这些实验体现了一些基本的问题,例如“探索”或“记忆”,其方式可以很容易地测试和迭代。具体来说,bsuite有两个主要目标:收集清晰、信息丰富和可扩展的问题,以捕捉设计高效和通用学习算法中的关键问题。通过代理在这些共享基准上的性能来研究代理行为。bsuite的当前实现实现了跨不同环境自动执行这些实验,并收集了相应的指标,这些指标可以简化DRL代理的培训。正如你所看到的,DeepMind一直非常积极地开发新的强化学习技术。OpenSpiel、SpriteWorld和bsuite对于开始强化学习之旅的研究团队来说是不可思议的资产。 在围棋上打败天下无敌手之后,DeepMind旗下的Alpha家族开始深入探究所有棋类,其中就包括国际象棋、日本将军棋。
2018年12月初,在AlphaZero诞生一周年之际,《自然》杂志以封面文发布了AlphaZero经过同行审议的完整论文,Deepmind创始人兼CEO哈萨比斯亲自执笔了这一论文。
AlphaGo Zero发布于2017年10月,而起真正受到重视是在去年12月初发布的《科学》杂志上,论文显示,AlphaGo Zero在三天内自学了三种不同的棋类游戏,包括国际象棋、围棋和日本将军棋,而且无需人工干预。这一成果震惊了国际象棋世界,几个小时内,AlphaGo Zero就成为了世界上最好的棋类玩家。
众所周知,在国际象棋方面,IBM的深蓝在20年前就打败了国际象棋大师,而后续的Stockfish和Komodo这些国际象棋程序也早已独霸国际象棋世界。在AlphaGo Zero发布之后,很多人质疑了其在国际象棋领域的价值。而本次的完整论文,对一些人认为机器算法下国际象棋没有价值的论调提出了几个措辞颇为严厉的批评。这是因为,在过去的12个月里,AlphaZero清楚展示了人类从未见过的一种智慧。
下面,就让我们通过论文来分析下AlphaZero。
深蓝、Stockfish和Komodo虽然能赢人类,但不能真正理解棋局文章指出,在过去的二十年里,用机器算法下国际象棋已经取得了很大进步。1997年,IBM公司的国际象棋程序“深蓝”(Deep Blue)在一场六局的比赛中击败了当时的人类世界冠军卡斯帕罗夫(Garry Kasparov)。现在看来,这一成就并不神秘。深蓝每秒可以计算2亿个位置。它从不疲倦,从不在计算中出错,也从不会忘记片刻之前的想法。
无论结果是好是坏,“深蓝”都像一台真正的机器,粗暴而物质化。它的计算能力远超过卡斯帕罗夫,但却无法真正从思维上超越他。在第一局的比赛中,深蓝贪婪地接受了卡斯帕罗夫用车换一名主教的牺牲,却在16步之后输了比赛。现在,诸如Stockfish和Komodo等当前世界上最强的国际象棋程序仍然在以这种方式下棋。它们喜欢吃掉对手的棋子;它们防守像钢铁一样强悍。但是,尽管这些国际象棋程序要比任何人类棋手强大得多,但并没有真正理解棋局本身的意义。
经过几十年的发展,人类大师关于棋类游戏的经验都被作为复杂的评估工具编进程序中,表明在下棋中该
寻求什么样的有利位置以及避免陷入什么样的不利境地。比如,王的安全性,棋子的活动、兵形、中心控制,以及
如何平衡利弊。但以往很多国际象棋程序却天生无视这些原则,给人留下的印象是野蛮粗暴的,这些程序速度快得惊人,但却完全缺乏洞察力。
AlphaGo Zero不仅打败了人类和所有程序,还拥有洞察力所有这些都随着机器学习的兴起而改变。AlphaZero通过与自己对弈并根据经验更新神经网络,从而发现了国际象棋的原理,并迅速成为史上最好的棋手。它不仅能够轻而易举地击败所有最强大的人类棋手,还能击败当时的计算机国际象棋世界冠军Stockfish。在与Stockfish进行的100场比赛中,AlphaZero取得28胜72平的好成绩。它没有输掉一场比赛。
最令人不可思议的是,AlphaZero似乎表达出一种天然的洞察力。它具备浪漫而富有攻击性的风格,以一种直观而优美的方式发挥着电脑所没有的作用。它会玩花招,冒险。在其中几局中,它使Stockfish瘫痪并玩弄它。当AlphaZero在第10局进行进攻时,它把自己的皇后佯退到棋盘的角落里,远离Stockfish的国王。通常来说,这并不是攻击皇后应该被放置的地方。
然而,这种奇怪的撤退行为充满了恶意,不管Stockfish如何应对,它都注定要失败。经过数十亿次残酷的计算后,AlphaZero几乎是在等待Stockfish意识到,自己的处境是多么无望,就像一头被击败的公牛面对斗牛士一样平静落败。大师们从未见过这样的机器。AlphaZero拥有精湛的技艺,同时也拥有机器的力量。这是人类第一次瞥见一种令人敬畏的新型智能。
很明显,AlphaZero
获胜靠的是更聪明的思维,而不是更快的思维。它每秒只计算6万个位置,而Stockfish会计算6千万个。它更明智,
知道该思考什么,该忽略什么。卡斯帕罗夫在《科学》杂志文章附带的一篇评论中写道,AlphaZero通过自主发现国际象棋的原理,开发出一种“反映游戏真相”的玩法,而不是“程序员式的优先级和偏见”。
除了棋类,AlphaZero还能做什么?现在的问题是,机器学习能否帮助人类发现所关心问题的真相?比如像癌症和意识、免疫系统之谜、基因组之谜等科学和医学尚未解决的重大问题。
早期迹象令人鼓舞。去年8月份,《自然医学》上的两篇文章探讨了机器学习如何应用于医学诊断。在一项研究中,DeepMind研究人员与伦敦莫尔菲尔德眼科医院(Moorfields Eye Hospital)的临床医生合作,开发出一种深度学习算法,可以准确地对各种视网膜病变进行分类。
另一篇文章也涉及一种机器学习算法,其能够确定急诊室病人的CT扫描是否显现出中风、颅内出血或其他重要神经疾病的迹象。对于中风患者来说,每一分钟都很重要;治疗耽误的时间越长,结果就越糟。新算法的准确性堪比人类专家,而且比人类专家快150倍。一个更快的诊断有助于医生对最紧急病例进行快速分类,并由人类放射科医生进行复查。
然而令人沮丧的是,机器学习算法还无法清晰表达它们的想法。我们不知道它们如何得出结论,所以也就无从确定能否信任机器。AlphaZero似乎已经发现了一些有关国际象棋的重要原则,但它无法与我们分享这种洞察力。作为人类,我们想要的不仅仅是答案,我们想要的是洞察力。从现在起,这将成为我们与电脑互动交流的开始。
事实上,这一情况在数学领域中早有耳闻。四色映射定理就是这样一个长期存在的数学问题。该定理指出在一定的合理约束条件下,有关相邻国家的任何地图都可以只使用四种颜色进行着色,这样相邻两个国家的颜色就不会相同。
虽然人们最终在计算机帮助下于1977年证明了四色映射定理,但是没有人能够检验论证中的所有步骤。从那以后,这个定理的证明得到了验证和简化,但仍有一些部分需要进行蛮力计算。这种发展使许多数学家感到恼火。他们不需要确认四色定理是正确的,但他们想知道为什么这是真的,但是证明没有帮助。
畅想未来:通用算法何时到来? 但是设想有一天,也许就在不久的将来,AlphaZero已经发展成为一种更通用的解决问题算法,其将拥有至高无上的洞察力,它能够拿出漂亮的证据,就像AlphaZero与Stockfish对弈时一样优雅,而且每一个证明都会揭示为什么定理是正确的。
对于人类数学家和科学家来说,这一天将标志着一个新时代的到来。机器的速度越来越快,相比之下人类神经元却以毫秒级的速度缓慢运转,我们再也跟不上机器的理解速度,人类洞察力的黎明可能很快就会变成黄昏。
无论是基因调控或癌症,还是免疫系统的编排,抑或是亚原子粒子的运动,其中或许还存在有待于发现的更深层模式。假设这些模式需要超越人类的更高智能来预测,而AlphaZero的继任者又能够识别并理解它们,那么在我们人类看来算法就像是一个神谕。
或许未来,我们不再明白为什么计算机的结论总是正确的,但我们可以通过实验和观察来检验它的计算和预测。科学将把我们的角色降低到旁观者的角色,在惊奇和困惑中目瞪口呆。
也许最终我们不再纠结于人类自身关于洞察力的匮乏。毕竟机器算法将能够治愈我们所有的疾病,解决我们所有的科学问题,并让我们所有的一切顺利前行。在我们作为智人存在的最初30万年时间里,我们在没有多少洞察力的情况下一样生存得相当好。我们将自豪地回忆起人类洞察力的黄金时代,这段几千年的辉煌插曲就发生在我们不理解的过去和我们不可思议的未来之间。
Alpha家族高手炼成记Alpha家族系列出自DeepMind公司,这家公司是2010年由杰米斯·哈萨比斯,谢恩·列格和穆斯塔法·苏莱曼创立的。在2014年,DeepMind荣获了剑桥大学计算机实验室的“年度公司”奖项。2014年1月26日,Google宣布收购DeepMind科技,收购的价格大概为4亿美元。
显然,DeepMind真正被全球熟知是在第一次人机大战之后,从2016年的那场对弈之后,DeepMind旗下的围棋
AI就开始了超神之路。
2016年1月27日,AlphaGo在没有任何让子的情况下,以5:0完胜欧洲围棋冠军、职业二段选手樊麾。在围棋
人工智能领域,实现了一次史无前例的突破。计算机程序能在不让子的情况下,在完整的围棋竞技中击败专业选手,这是第一次。
2016年3月,阿尔法围棋与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜,举世哗然,人工智能概念开始被大众熟知。
2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册账号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩;
2017年5月,在中国乌镇围棋峰会上,阿尔法围棋以3比0的总比分战胜排名世界第一的世界围棋冠军柯洁。在这次围棋峰会期间的2017年5月26日,阿尔法围棋还战胜了由陈耀烨、唐韦星、周睿羊、时越、芈昱廷五位世界冠军组成的围棋团队。在柯洁与阿尔法围棋的人机大战之后,阿尔法围棋团队宣布阿尔法围棋将不再参加围棋比赛。
2017年10月18日,DeepMind团队公布了最强版AlphaGo ,代号AlphaGo Zero。它的独门秘籍是“自学成才”。而且,是从一张白纸开始,零基础学习,在短短3天内,成为顶级高手。经过短短3天的自我训练,AlphaGo Zero就强势打败了此前战胜李世石的旧版AlphaGo,战绩是100:0的。
2017年12月5日,AlphaGo Zero迎来升级,这个被称为AlphaZero的程序在三天内自学了三种不同的棋类游戏,包括国际象棋、围棋和日本的将军棋,无需人工干预,一篇描述这一成就的论文今年12月初在《科学》杂志发表。在AlphaZero之外,DeepMind在医疗领域还打造了一个名为AlphaFold的AI系统,它能够应对当今生物学中最大的挑战之一:模拟蛋白质的形状。
2018年12月,AlphaGo Zero登上《自然》杂志封面,完整论文首次公开。
知乎专栏同步发布:
https://zhuanlan.zhihu.com/p/41133862本来打算自己写写的,但是发现了
David Foster的神作,看了就懂了。我也就不说啥了。

看不清的话,原图在后面的连接也可以找到。
没懂?!!!那我再解释下。
AlphaGo Zero主要由三个部分组成:自我博弈(self-play),训练和评估。和AlphaGo 比较,AlphaZero最大的区别在于,并没有采用专家样本进行训练。通过自己和自己玩的方式产生出训练样本,通过产生的样本进行训练;更新的网络和更新前的网络比赛进行评估。
在开始的时候,整个系统开始依照当前最好的网络参数进行自我博弈,那么假设进行了10000局的比赛,收集自我博弈过程中所得到的数据。这些数据当中包括:每一次的棋局状态以及在此状态下各个动作的概率(由蒙特卡罗搜索树得到);每一局的获胜得分以及所有棋局结束后的累积得分(胜利的+1分,失败得-1分,最后各自累加得分),得到的数据全部会被放到一个大小为500000的数据存储当中;然后随机的从这个数据当中采样2048个样本,1000次迭代更新网络。更新之后对网络进行评估:采用当前被更新的网络和未更新的网络进行比赛400局,根据比赛的胜率来决定是否要接受当前更新的网络。如果被更新的网络获得了超过55%的胜率,那么接收该被更新的网络,否则不接受。
那么我们首先来看一下AlphaZero的输入的棋局状态到底是什么。如图所示,是一个大小为19*19*17的数据,表示的是17张大小为19*19(和棋盘的大小相等)的特征图。其中,8张属于白子,8张属于黑子,标记为1的地方表示有子,否则标记为0 。剩下的一张用全1或者是全0表示当前轮到 黑子还是白子了。构成的这个数据表示游戏的状态输入到网络当中进行训练。

那么我们来看一下,AlphaZero的网络到底是怎么样的呢?
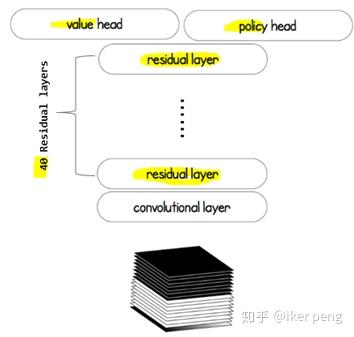
这个网络主要由三个部分组成:
由40层残差网络构成的特征提取网络(身体),以及价值网络以及策略网络(两个头)。该网络当中价值网络所输出的值作为当前的状态的价值估计; 策略网络的输出作为一个状态到动作的映射概率。而这两个部分的输出都被引入到蒙特卡罗搜索树当中,
强化学习用来
指导最终的下棋决策。那么显然,价值网络输出的是一个1D的标量值,在-1到1之间;策略网络输出的是一个19*19*1的特征图,其中的每一个点表示的是下棋到该位置的概率。那我们来看一下,该网络是如何指导蒙特卡罗搜索树的。
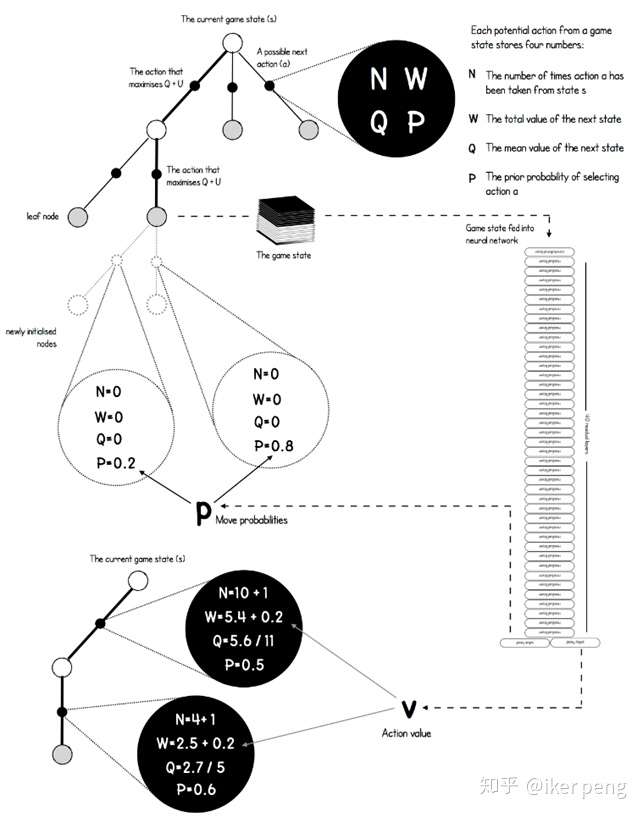
如图所示,在图中的搜索树当中,黑色的点表示的是从一个状态过渡到另一个状态的动作a;其余的节点表示的是棋局的状态,也就是之前所说的输入。从一个非叶子节点的状态开始,往往存在多种可能的行动,而其中的状态节点a具有4种属性,他们决定了到底应该如何选择。具体来讲,其中的N表示的是到目前为止,该动作节点被访问的次数;P表示网络预测出来的选择该节点的概率;W表示下一个状态的总的价值,而价值网络输出的动作的价值会被累及到这个值当中;这个值除以被访问到的次数就等于平均的价值Q。实际上,还会给Q加上一个U来起到探索更多的动作的效果。我想应该是非常清楚的。那么如何根据构建出来的搜索树进行下棋的步骤呢?在一定的阈值范围内(比如说,1000个迭代之前),采用最大化Q函数的方式来选择动作;那么当大于这个阈值之后采用蒙特卡罗搜索树的方式(例如PUCT算法,也就是根据概率和被访问的次数)来选择执行的动作。
那我们来看一下蒙特卡罗搜索树在这里面时如何实现的。首先是其中的节点:
class Node:
def __init__(self, parent=None, proba=None, move=None):
self.p = proba
self.n = 0
self.w = 0
self.q = 0
self.children = []
self.parent = parent
self.move = move
其中主要为之前所说的4个属性以及父子节点的指针。而最后一个move指出了在当前状态下的合法下棋步骤。在训练的过程中,这些值都会被更新,那么在更新之后如何通过他们来进行动作的选择呢?
def select(nodes, c_puct=C_PUCT):
" Optimized version of the selection based of the PUCT formula "
total_count = 0
for i in range(nodes.shape[0]):
total_count += nodes[1]
action_scores = np.zeros(nodes.shape[0])
for i in range(nodes.shape[0]):
action_scores = nodes[0] + c_puct * nodes[2] * \
(np.sqrt(total_count) / (1 + nodes[1]))
equals = np.where(action_scores == np.max(action_scores))[0]
if equals.shape[0] > 0:
return np.random.choice(equals)
return equals[0]
这里表示的是对于任何一个节点,从其所有的子节点当中,通过PUCT算法找出最大得分的那个节点。在这个得分action_scores的计算过程中,网络预测的概率和该节点被访问的次数都有被考虑。对于被访问到的非叶子节点继续进行扩展;而如果是叶子节点则进行最终的评估。至于其中的残差网络模块,价值网络,策略网络就不再一一叙述了。详细参考:
https://github.com/dylandjian/superGogithub.com
References:
https://medium.com/applied-data-science/alphago-zero-explained-in-one-diagram-365f5abf67e0



